A user reported an issue with their PostgreSQL disk becoming 95% full.
Before taking action we needed to understand:
- If Timescale chunks were being compressed in a timely manner.
- If Timescale data retention was removing "expired" chunks in a timely manner.
How to diagnose
1. Determine the Timescale compression period
In Hub 2.x the Timescale compression period is always set to match the Kafka retention period.
You can find the Kafka retention period in the log.retention.hours setting in any Hub node's Kafka broker properties file, which by default is installed at /opt/hub/hub-current/services/kafka-2.12-2.7.0/conf/server.properties (but may be elsewhere depending on user installation preferences).
The default value for this setting is 72 hours (i.e. 3 days).
What this means is that we are asking:
- Kafka to retain data for 72 hours before deleting it permanently.
- Timescale to leave the most recent 72 hours of data uncompressed, and compress anything older than that.
NOTE:
The Timescale compression period is set to match the Kafka retention period
to avoid Timescale compressing chunks containing any old data still being
ingested from Kafka.
Compressed chunks can't be modified (in Timescale 1.7.x) so compressing
prematurely would cause subsequent insertions to fail.
In normal operation this is not a concern, but we want to give ourselves
a good chance of catching up in situations where Kafka has been up and
accepting inbound data (cluster wide), but Persistence Daemon has been
down (maybe on just one node during patching).
2. Determine whether Timescale compression is keeping up with incoming data
In Hub 2.x all Timescale hypertable chunks are 1 hour in duration.
So to determine whether or not compression is keeping up we want to look for any tables that have significantly more uncompressed chunks than specified by the Timescale compression period.
Log into each Hub node as the runtime user, which by default is hub, then run the following (after adjusting paths to suit user installation preferences):
cd /opt/hub/hub-current/services/postgres-timescale-12.x.y.z
./run-psql.sh
Then run this SQL:
\c hub;
SELECT hypertable_name, compression_status, COUNT(*)
FROM timescaledb_information.compressed_chunk_stats
GROUP BY hypertable_name, compression_status
HAVING compression_status = 'Uncompressed'
ORDER BY hypertable_name, compression_status;
The result will look something like this:
hypertable_name | compression_status | count
----------------------+--------------------+-------
metric_series_000002 | Uncompressed | 1
metric_series_000005 | Uncompressed | 1
metric_series_000009 | Uncompressed | 1
metric_series_000010 | Uncompressed | 1
What we're looking for is any `count` value significantly higher than the number of hours specified by the Timescale compression period.
So in the example from above anything a lot higher than 72 indicates that compression is not keeping up.
You can of course ask PostgreSQL to do this filtering for you with something like:
SELECT hypertable_name, compression_status, COUNT(*)
FROM timescaledb_information.compressed_chunk_stats
GROUP BY hypertable_name, compression_status
HAVING compression_status = 'Uncompressed'
-- Find hypertables with chunks that have remained uncompressed for 12 hours,
-- assuming a 72 hour compression period
AND COUNT(*) >= 84
ORDER BY hypertable_name, compression_status;
To exit psql type '\q'.
3. Determine what the Timescale data retention period is
We allow users to change the Timescale data retention period in the Hub's Web Console; so you can check it there too.
Navigate using the left hand menu to "Administration / Storage".
It looks like this:
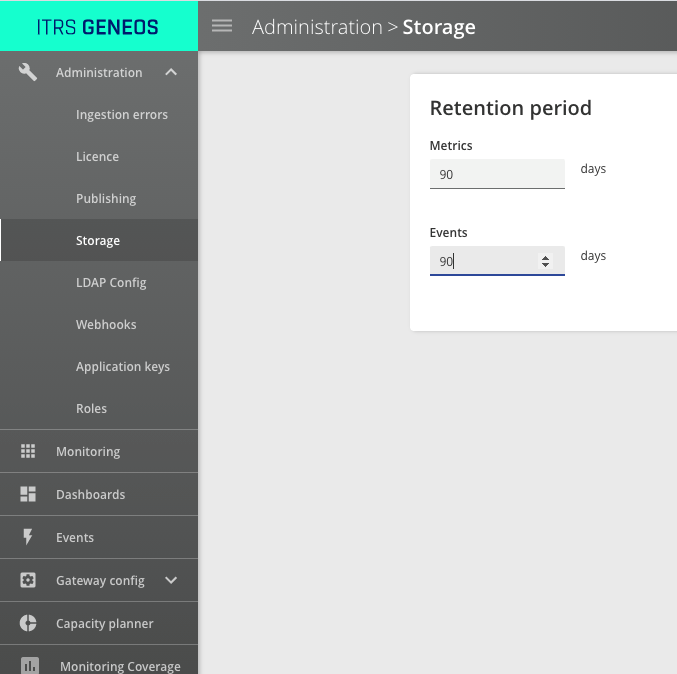
In this example the retention period is set to 90 days for both metric and event data. So we are asking Timescale to retain data for 90 days before deleting it permanently.
4. Determine whether Timescale data retention is cleaning up old data
To determine whether or not data retention is keeping up, we want to look for any hypertable chunks that contain data older than specified by the Timescale retention period.
Log into each Hub node as the runtime user, which by default is hub then run the following (after adjusting paths to suit user installation preferences):
cd /opt/hub/hub-current/services/postgres-timescale-12.x.y.z
./run-psql.sh
Then run this SQL:
\c hub;
SELECT format('%1$I.%2$I', ch.schema_name, ch.table_name)::regclass AS chunk,
format('%1$I.%2$I', ht.schema_name, ht.table_name)::regclass AS hypertable,
tsrange(CASE WHEN sl.range_start = -9223372036854775808 THEN NULL
ELSE _timescaledb_internal.to_timestamp_without_timezone(sl.range_start) END,
CASE WHEN sl.range_end = 9223372036854775807 THEN NULL
ELSE _timescaledb_internal.to_timestamp_without_timezone(sl.range_end) END)
AS time_range,
(SELECT nspname FROM pg_class JOIN pg_namespace ns ON relnamespace = ns.oid
WHERE chunk_id = pg_class.oid) AS tablespace
FROM _timescaledb_catalog.chunk ch
JOIN _timescaledb_catalog.hypertable ht ON ch.hypertable_id = ht.id
JOIN _timescaledb_catalog.dimension di ON di.hypertable_id = ht.id
JOIN _timescaledb_catalog.chunk_constraint cn ON cn.chunk_id = ch.id
JOIN _timescaledb_catalog.dimension_slice sl ON cn.dimension_slice_id = sl.id
WHERE column_type = 'timestamp'::regtype;
The result will look something like this:
chunk | hypertable | time_range | tablespace
----------------------------------------+----------------------+-----------------------------------------------+------------
_timescaledb_internal._hyper_3_1_chunk | metric_series_000002 | ["2021-09-29 07:00:00","2021-09-29 08:00:00") |
_timescaledb_internal._hyper_5_2_chunk | metric_series_000005 | ["2021-09-29 07:00:00","2021-09-29 08:00:00") |
_timescaledb_internal._hyper_7_3_chunk | metric_series_000009 | ["2021-09-29 07:00:00","2021-09-29 08:00:00") |
_timescaledb_internal._hyper_9_4_chunk | metric_series_000010 | ["2021-09-29 07:00:00","2021-09-29 08:00:00") |
What we're looking for is any time_range significantly older than now (UTC) minus the number of days specified by the Timescale retention period.
To exit psql type '\q'.
The query above directly from the Timescale team and can be found here:
https://github.com/timescale/timescaledb-extras/blob/master/views/chunks.sql
It could be improved to:
- Return the time range per hypertable only (not per chunk).
- Allow filtering based on the time range.
For a broader view of what's going on check the result of the Timescale jobs.
5. Look for issues with job scheduling
Log into each Hub node as the runtime user, which by default is hub then run the following (after adjusting paths to suit user installation preferences):
cd /opt/hub/hub-current/services/postgres-timescale-12.x.y.z
./run-psql.sh
Then run this SQL:
\c hub;
SELECT *
FROM timescaledb_information.policy_stats;
The result will look something like this:
hypertable | job_id | job_type | last_run_success | last_finish | last_successful_finish | last_start | next_start | total_runs | total_failures
----------------------+--------+-------------+------------------+-------------------------------+-------------------------------+-------------------------------+-------------------------------+------------+----------------
events | 1000 | drop_chunks | t | 2021-09-29 06:59:49.805906+00 | 2021-09-29 06:59:49.805906+00 | 2021-09-29 06:59:49.786055+00 | 2021-09-30 06:59:49.805906+00 | 4 | 0
metric_series_000002 | 1001 | drop_chunks | t | 2021-09-29 07:04:35.084192+00 | 2021-09-29 07:04:35.084192+00 | 2021-09-29 07:04:35.07708+00 | 2021-09-30 07:04:35.084192+00 | 1 | 0
metric_series_000005 | 1002 | drop_chunks | t | 2021-09-29 07:04:35.084735+00 | 2021-09-29 07:04:35.084735+00 | 2021-09-29 07:04:35.078498+00 | 2021-09-30 07:04:35.084735+00 | 1 | 0
metric_series_000009 | 1003 | drop_chunks | t | 2021-09-29 07:04:35.085443+00 | 2021-09-29 07:04:35.085443+00 | 2021-09-29 07:04:35.07932+00 | 2021-09-30 07:04:35.085443+00 | 1 | 0
metric_series_000010 | 1004 | drop_chunks | t | 2021-09-29 07:04:35.087844+00 | 2021-09-29 07:04:35.087844+00 | 2021-09-29 07:04:35.080177+00 | 2021-09-30 07:04:35.087844+00 | 1 | 0
What we're looking for is any row for which last_successful_finish is a long time in the past. This indicates that the job is never completing successfully.
To exit psql type '\q'.
Often jobs that have not completed recently will correspond in the PostgreSQL log with entries like the below:
2021-09-29 02:36:08.090 GMT [110499] WARNING: failed to launch job 4489 "Drop Chunks Background Job": out of background workers
2021-09-29 02:36:08.090 GMT [110499] WARNING: failed to launch job 3892 "Compress Chunks Background Job": out of background workers
Short-term solution
In this user's case the issue was that:
- Data compression was not keeping up
- However data retention was keeping up just fine.
Data compression was not keeping up due to insufficient CPU resource. In response to a previous support ticket we reduced the PostgreSQL timescaledb.max_background_workers setting to avoid all CPUs being pegged at high utilisation and requested that user provision more CPU capacity.
While waiting for additional CPU resource the solution is to reduce the data retention period in the Web Console (using the same page described in section 3 above).
If you want to be sure that the data retention policy has been applied, log into each Hub node as the runtime user, which by default is hub then run the following (after adjusting paths to suit user installation preferences):
cd /opt/hub/hub-current/services/postgres-timescale-12.x.y.z
./run-psql.sh
Then run this SQL:
\c hub;
SELECT *
FROM timescaledb_information.drop_chunks_policies;
The result will look something like this:
hypertable | older_than | cascade | job_id | schedule_interval | max_runtime | max_retries | retry_period | cascade_to_materializations
----------------------+--------------+---------+--------+-------------------+-------------+-------------+--------------+-----------------------------
events | (t,"1 day",) | f | 1000 | 1 day | 00:05:00 | -1 | 00:05:00 | f
metric_series_000002 | (t,"1 day",) | f | 1001 | 1 day | 00:05:00 | -1 | 00:05:00 | f
metric_series_000005 | (t,"1 day",) | f | 1002 | 1 day | 00:05:00 | -1 | 00:05:00 | f
metric_series_000009 | (t,"1 day",) | f | 1003 | 1 day | 00:05:00 | -1 | 00:05:00 | f
metric_series_000010 | (t,"1 day",) | f | 1004 | 1 day | 00:05:00 | -1 | 00:05:00 | f
The older_than column should match the data retention period you set in the Web Console.
You will notice that the schedule_interval is set to 1 day so if you have an urgent need to manually run data retention you can run the following:
Be careful, the following commands will PERMANENTLY delete data.
-- Update the interval to match your data retention period
SELECT drop_chunks(INTERVAL '90 days', table_name)
FROM _timescaledb_catalog.hypertable
WHERE schema_name = 'public';
If there are a LOT of hypertables you might find that this fails with "ERROR: out of shared memory" in which case the solution is to page through using `OFFSET` and `LIMIT`:
SELECT COUNT(*)
FROM _timescaledb_catalog.hypertable
WHERE schema_name = 'public';
SELECT drop_chunks(INTERVAL '90 days', table_name)
FROM
(
SELECT table_name
FROM _timescaledb_catalog.hypertable
WHERE schema_name = 'public'
ORDER BY table_name
OFFSET 0 LIMIT 500
) AS pageOfHypertables;
SELECT drop_chunks(INTERVAL '90 days', table_name)
FROM
(
SELECT table_name
FROM _timescaledb_catalog.hypertable
WHERE schema_name = 'public'
ORDER BY table_name OFFSET 500 LIMIT 500
) AS pageOfHypertables;
-- Keep going until OFFSET + LIMIT is >= than the hypertable count
Long-term solution
The long term solution in this user's case was to:
- Increase the core count on each node. They upgraded from 8 to 16 cores.
- Adjust the timescaledb.max_background_workers and max_parallel_workers PostgreSQL settings. timescaledb.max_background_workers probably needs to be something more like 10 in user's case. Refer to the Timescale docs.
- The setting above might be set correctly by hubctl setup reconfigure via this PostgreSQL configuration script; but we should check before and after configuration to be sure.
- Monitor to ensure that:
- Data compression and retention jobs complete in a timely manner.
- CPU utilisation doesn't get too high.
- When the system appears stable the user should be able to increase their data retention back to the preferred 90 days.
Comments
0 comments
Please sign in to leave a comment.