Extractor plugin
Since GA4.4 it has been possible to extract data from JSON file structures using the Extractor plugin. This can be done either through a stream provided by Webmon or directly from a file.
Configuration
Before extraction, the JSON data is converted into XML, and the structure changes accordingly. In the conversion an additional top layer (/object) is added to the tree.
So looking at this:
{
"content": {
"data": {
"agents_away": 0,
"agents_invisible": 0,
"agents_online": 1
},
"department_id": null,
"topic": "agents",
"type": "update"
},
"status_code": 200
}
This will be converted into:
<?xml version="1.0" encoding="UTF-8"?>
<object>
<content>
<data>
<agents_away>0</agents_away>
<agents_invisible>0</agents_invisible>
<agents_online>1</agents_online>
</data>
<department_id/>
<topic>agents</topic>
<type>update</type>
</content>
<status_code>200</status_code>
</object>
As you can see, all headers are converted straight into tag names instead of attributes, which makes it more difficult to rotate around children tags. In normal XML we would rotate around all children in data by using /object/content/data/tr (or similar end tag) row names would be created for each child seen and we could only extract the value.
In this case we can rotate around /object/content/data/* where row names would be created using "name()" and value would be extracted using "text()"
The finished XML would look like this:
<sampler name="Extractor JSON file">
<plugin>
<extractor>
<source>
<sourceFileName>
<name>
<data>/path/to/faq_extract_json.json</data>
</name>
</sourceFileName>
</source>
<views>
<view>
<name>
<data>Test</data>
</name>
<template>
<custom>
<format>
<json>
<method>
<xpath>
<headlines>
<headline>
<name>
<static>
<data>Topic</data>
</static>
</name>
<value>
<xpath>
<xpath>/object/content/topic</xpath>
</xpath>
</value>
</headline>
</headlines>
<columns>
<column>
<name>
<static>
<data>name</data>
</static>
</name>
</column>
<column>
<name>
<static>
<data>value</data>
</static>
</name>
</column>
</columns>
<rows>
<xpath>/object/content/data/*</xpath>
<row>
<name>
<xpath>
<xpath>name()</xpath>
</xpath>
</name>
<cells>
<cell>
<value>
<xpath>
<xpath>text()</xpath>
</xpath>
</value>
</cell>
</cells>
</row>
</rows>
</xpath>
</method>
</json>
</format>
</custom>
</template>
</view>
</views>
</extractor>
</plugin>
<debug>
<setting>*</setting>
</debug>
</sampler>
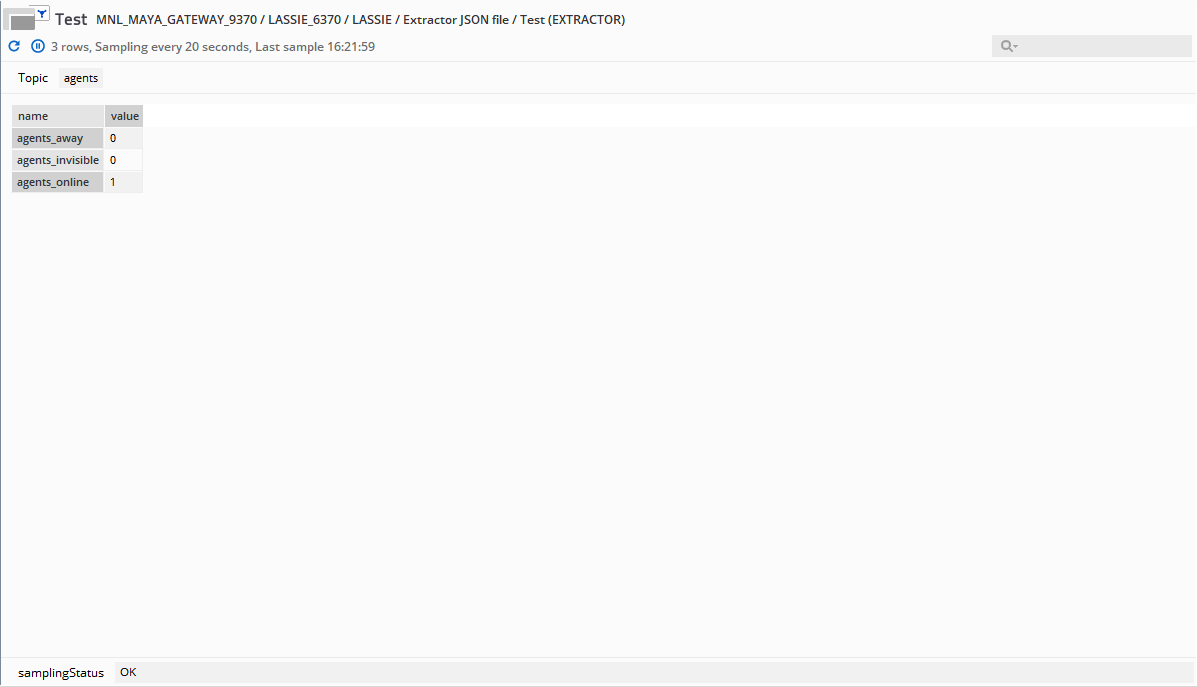
The dataview would look like this:
Comments
0 comments
Please sign in to leave a comment.