|
The netprobe uses some function of the XPath 1.0 spec. |
|
Ever since the netprobe was enhanced to be able to read files locally as opposed to Webmon there have been several scenarios in which to parse xml files to gather information quickly. Work has even happened with partners, so they are reformatting their xml data such that it makes more sense to parse. There are a couple of tips/tricks that exist in the XML 1.0 RFC that we don't have in our documentation, as why would we document an RFC. One thing to note is the difference between an element and an attribute. An attribute is contained within the xml tag and is usually reasonably static. Typically something like a name or id would be defined as an attribute. Otherwise, you will be getting values from xml elements. Random XML
<element attributeName="attributeValue">SomeText</element>
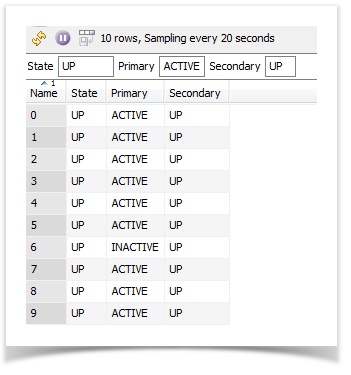
Useful functions: child::* This will iterate through all the child nodes. In the above example, the list has multiple items in it. As opposed to creating an extractor that lists them all out, I can use the child function to iterate over the list. name() This will return the name of the element. When using the example above with child the rownames could then be item1, item2 respectively. text() This returns the text contained by the start and end tags of an element. @<attribute> This returns the value of the attribute being accessed. (Replace <attribute> with its name) Attached is an xml file to monitor as well as an extractor example that creates a table and some headline values. XML to monitor
<?xml version="1.0" encoding="utf-8"?> Sampler XML<sampler name="Extractor">
|
|
|
|
Comments
0 comments
Please sign in to leave a comment.