
|
The JSON parsing feature has been available in Netprobe version GA4.4 and above. This article will discuss how to use Webmon and Extractor plugins to monitor JSON format contents on a website. |
|
In this example we will be monitoring and extracting information from the following website: From the API, we have picked the Announced Endpoint to obtain 30 days data with JSON format output. The full URL would become: 1. Configure Webmon plugin and enable Data Transfer In Web-Mon plugin, the URL should be broken down into below options:
Having downloaded the page in Webmon, we then need pass it as a data stream to Extractor. To enable this you will need to implement the following setting:
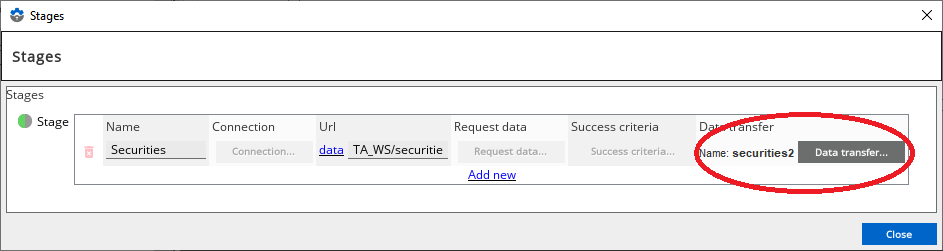
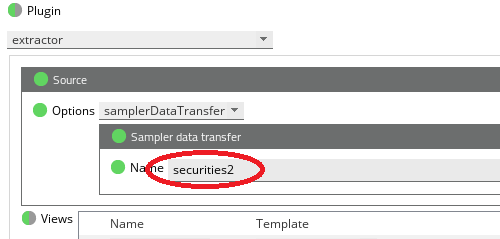
The Data Transfer Name setting (configured to securities2) can be seen in the below screenshot:
2. Configure Extractor plugin and set the source of information Moving on to the setup of the Extractor plugin, we will need to specify the source of data, which will be from the Webmon plugin in this case. This can be enabled as follows:
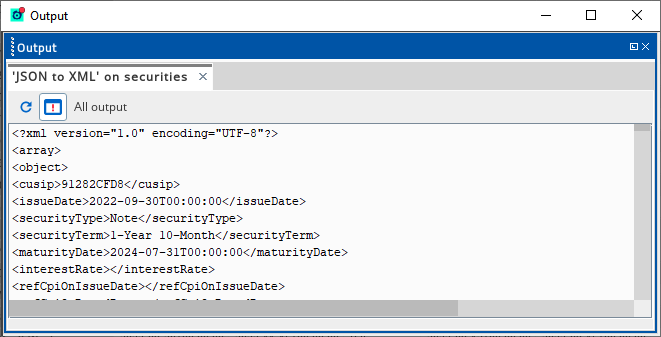
And give the name of the Data Transfer implemented in Webmon, in this example it would be called securities2 3. Enable "showmenu" debug in Extractor plugin (optional) It will be helpful to see how the JSON tags are converted to XML format. The "showmenu" option can be entered at the Debug tab for the Extractor sampler. On the Active Console, it will enable a right-click menu with a Debug => JSON to XML option.
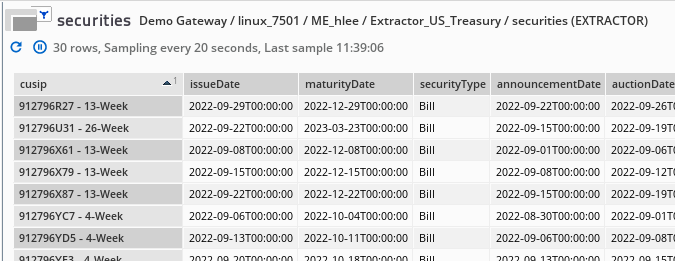
4. Extracting the JSON tags After setting up the source to come from the Webmon plugin, we can then extract individual or recursive tags with the Extractor plugin. In this example, we want to display the source data in tabular format on the Active Console, and use "cusip" as the first column. As the above JSON to XML debug shows, the XPath for the "cusip" column can be represented by "/array/object/cusip". However, when we examine the raw data more closely, we encounter an issue that "cusip" may not be unique. To overcome this, we have selected to concatenate it with the "securityTerm" column (represented by "/array/object/securityTerm") to become the first column. Then the remaining columns (issueDate, MaturityDate, securityType, ...) are quite straight-forward to configure. We have attached the samplers in XML code at the bottom of the article, so users can experiment and reuse the configuration. The output on the Active Console is provided below:
|
|
Older Netprobe versionsIf the Netprobe is older than version GA4.4, Extractor plugin will return message ERROR: Config problem: Unknown format selected at the samplingStatus headline. Users should upgrade the Netprobe version in this case. |
|
Further Reading
|
Comments
0 comments
Please sign in to leave a comment.